THE AUDITORY MODELING TOOLBOX
This documentation page applies to an outdated AMT version (1.1.0). Click here for the most recent page.
sig_competingtalkers - Load one of several test signals
Usage
s=sig_competingtalkers(signame); [s,fs]=sig_competingtalkers(signame);
Description
sig_competingtalkers(signame) loads one of several test signals consisting of competing talkers. All the talkers are taken from the TIMIT speech corpus https://doi.org/10.35111/17gk-bn40 and filtered by HRTFs recorded in the Oldenburg lab with a Bruel and Kjaer Type 4128C head and torso simulator (Kayser et al., 2009). An exception is 'one_speaker_reverb', see description below.
The signals have 2 channels and are provided with a sampling rate of 16 kHz.
[sig,fs]=sig_competingtalkers(signame) additionally returns the sampling frequency fs.
The parameter signame can be:
| 'one_of_three' | Talker spatialized at the azimuth angle of 30 degrees. |
| 'two_of_three' | Talker spatialized at the azimuth angle of 0 degrees. |
| 'three_of_three' | Talker spatialized at the azimuth angle of -30 degrees. |
| 'one_speaker_reverb' | Talker spatialized at horizontal position of 45 degrees by applying a binaural set of room impulse responses (BRIR) of an office room from a database recorded with hearing-aid microphones behind the ear. |
| 'two_speakers' | Two simultanous talkers spatialized at the azimuth angles of -30 and 30 degrees. |
| 'five_speakers' | Five simultanous talkers spatialized at the azimuth angles of -80, -30, 0, 30, and 80 degrees. |
| 'bnoise' | Speech-shaped binaural noise. |
Examples:
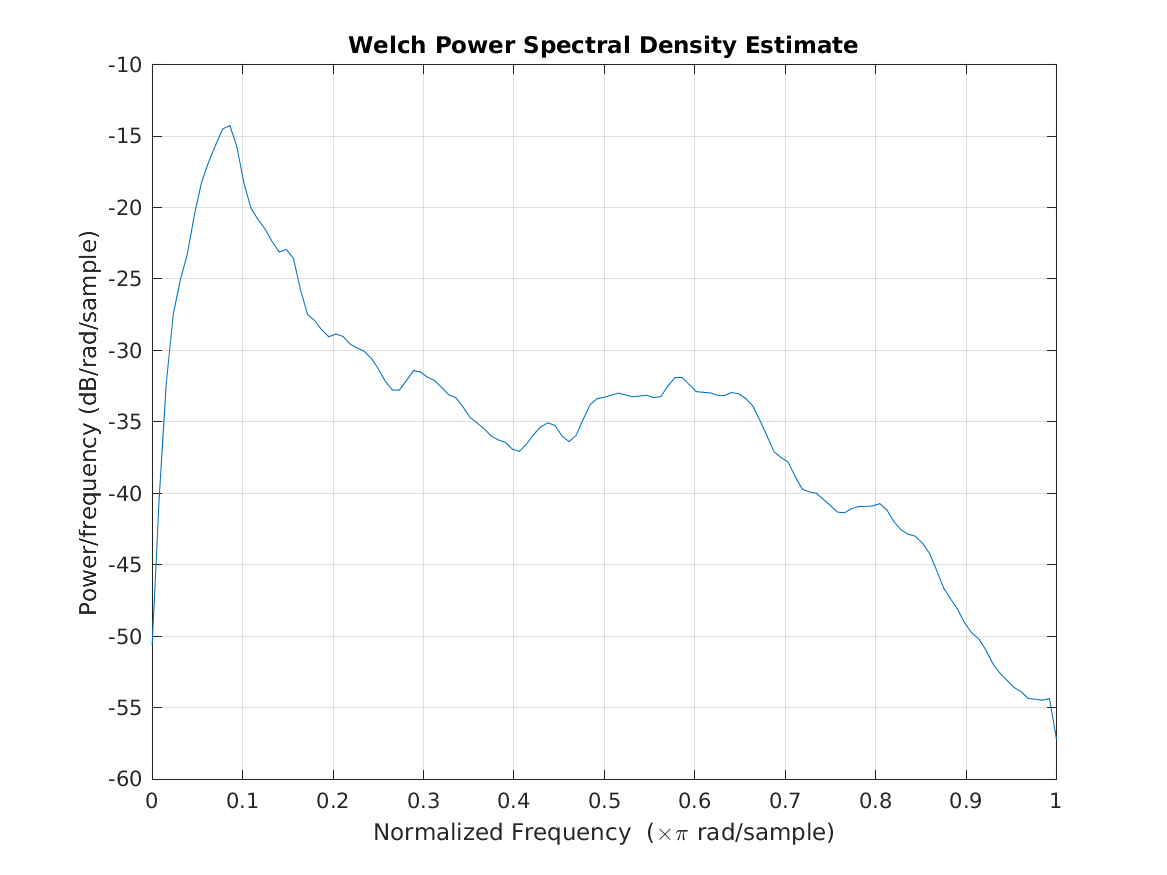
The following plot shows an estimate of the power spectral density of the first channels of the speech shaped noise:
s=sig_competingtalkers('bnoise');
pwelch(s(:,1),hamming(150));
This code produces the following output:
Model: sig_competingtalkers. Downloading auxiliary data: bnoise.wav Searching in current AMT version... Searching in previous AMT versions... Trying version amt-1.0.0 Found data in version: amt-1.0.0















Build with Bootstrap